Programs running on the Cell Broadband Engine’s nine processor elements typically partition the work among the available processor elements.
- processing-load distribution,
- program structure,
- program data flow and data access patterns,
- cost, in time and complexity of code movement and data movement among processors, and
- cost of loading the bus and bus attachments.
In the PPE-centric model, the main application runs on the PPE, and individual tasks are off-loaded to the SPEs. The PPE then waits for, and coordinates, the results returning from the SPEs. This model fits an application with serial data and parallel computation.
In the SPE-centric model, most of the application code is distributed among the SPEs. The PPE acts as a centralized resource manager for the SPEs. Each SPE fetches its next work item from main storage (or its own local store) when it completes its current work.
- the multistage pipeline model,
- the parallel stages model, and
- the services model.
If a task requires sequential stages, the SPEs can act as a multistage pipeline. The left side of Figure 2 shows a multistage pipeline. Here, the stream of data is sent into the first SPE, which performs the first stage of the processing. The first SPE then passes the data to the next SPE for the next stage of processing. After the last SPE has done the final stage of processing on its data, that data is returned to the PPE. As with any pipeline architecture, parallel processing occurs, with various portions of data in different stages of being processed.
Multistage pipelining is typically avoided because of the difficulty of load balancing. In addition, the multistage model increases the data-movement requirement because data must be moved for each stage of the pipeline.
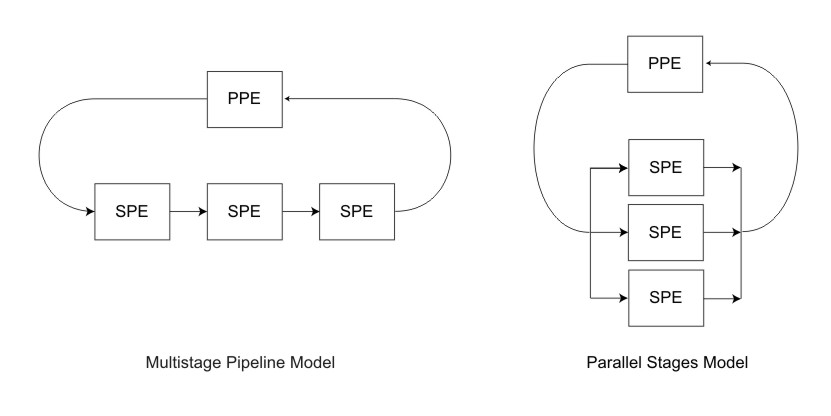
If the task to be performed is not a multistage task, but a task in which there is a large amount of data that can be partitioned and acted on at the same time, then it typically make sense to use SPEs to process different portions of that data in parallel. This parallel stages model is shown on the right side of Figure 2.
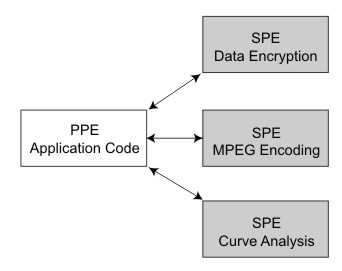
The third way in which SPEs can be used in a PPE-centric model is the services model. In the services model, the PPE assigns different services to different SPEs, and the PPE’s main process calls upon the appropriate SPE when a particular service is needed.
For a more detailed view of programming models, see Programming models.