When transferring data in parallel with the computation, double buffering can reduce the time lost to data transfer by overlapping it with the computation time. The ALF runtime implementation on Cell BE architecture supports three different kinds of double buffering schemes.
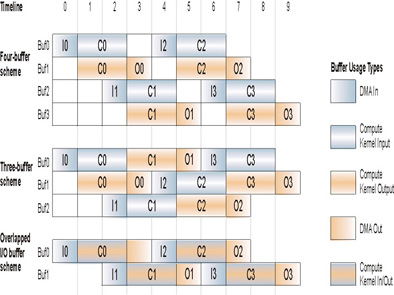
See Figure 1 for an illustration of how double buffering works inside ALF. The ALF runtime evaluates each work block and decides which buffering scheme is most efficient. At each decision point, if the conditions are met, that buffering scheme is used. The ALF runtime first checks if the work block uses the overlapped I/O buffer. If the overlapped I/O buffer is not used, the ALF runtime next checks the conditions for the four-buffer scheme, then the conditions of the three-buffer scheme. If the conditions for neither scheme are met, the ALF runtime does not use double buffering. If the work block uses the overlapped I/O buffer, the ALF runtime first checks the conditions for the overlapped I/O buffer scheme, and if those conditions are not met, double buffering is not used.
These examples use the following assumptions:
- All SPUs have 256 KB of local memory.
- 16 KB of memory is used for code and runtime data including stack, the task context buffer, and the data transfer list. This leaves 240 KB of local storage for the work block buffers.
- Transferring data in or out of accelerator memory takes one unit of time and each computation takes two units of time.
- The input buffer size of the work block is represented as in_size, the output buffer size as out_size, and the overlapped I/O buffer size as overlap_size.
- There are three computations to be done on three inputs, which produces three outputs.
Buffer schemes
The conditions and decision tree are further explained in the examples below.
- Four-buffer scheme: In the four-buffer scheme, two buffers are
dedicated for input data and two buffers are dedicated for output data. This
buffer use is shown in the Four-buffer scheme section of Figure 1.
- Conditions satisfied: The ALF runtime chooses the four-buffer scheme if the work block does not use the overlapped I/O buffer and the buffer sizes satisfy the following condition: 2*(in_size + out_size) <= 240 KB.
- Conditions not satisfied: If the buffer sizes do not satisfy the four-buffer scheme condition, the ALF runtime will check if the buffer sizes satisfy the conditions of the three-buffer scheme.
- Three-buffer scheme: In the three-buffer scheme, the buffer is
divided into three equally sized buffers of the size max(in_size, out_size).
The buffers in this scheme are used for both input and output as shown in
the Three-buffer scheme section of Figure 1.
This scheme requires the output data movement of the previous result to be
finished before the input data movement of the next work block starts, so
the DMA operations must be done in order. The advantage of this approach is
that for a specific work block, if the input and output buffer are almost
the same size, the total effective buffer size can be 2*240/3 = 160 KB.
- Conditions satisfied: The ALF runtime chooses the three-buffer scheme if the work block does not use the overlapped I/O buffer and the buffer sizes satisfy the following condition: 3*max(in_size, out_size) <= 240 KB.
- Conditions not satisfied: If the conditions are not satisfied, the single-buffer scheme is used.
- Overlapped I/O buffer scheme: In the overlapped I/O buffer scheme,
two contiguous buffers are allocated as shown in the Overlapped I/O buffer
scheme section of Figure 1.
The overlapped I/O buffer scheme requires the output data movement of the
previous result to be finished before the input data movement of the next
work block starts.
- Conditions satisfied: The ALF runtime chooses the overlapped I/O buffer scheme if the work block uses the overlapped I/O buffer and the buffer sizes satisfy the following condition: 2*(in_size + overlap_size + out_size) <= 240 KB.
- Conditions not satisfied: If the conditions are not satisfied, the single-buffer scheme is used.
- Single-buffer scheme: If none of the cases outlined above can be satisfied, double buffering is not used, but performance might not be optimal.
When creating buffers and data partitions, remember the conditions of these buffering schemes. If your buffer sizes can meet the conditions required for double buffering, it can result in a performance gain, but double buffering does not double the performances in all cases. When the time periods required by data movements and computation are significantly different, the problem becomes either I/O-bound or computing-bound. In this case, enlarging the buffers to allow more data for a single computation might improve the performance even with a single buffer.