Old ARC Cluster
Looking for the documentation of the old ARC
cluster V2b, or the older ARC cluster V2
or the oldest ARC Cluster V1?
Hardware & Software Status

READ THIS BEFORE YOU RUN ANYTHING: Running Jobs (via Slurm)
(1) Notice: Store large data files in the Beegfs file
system and not your home directory. The home directory is for
programs and small data files, which should not exceed 40GB
altogether. This upper limited is quata controlled, i.e., if
exceeding it, you will have to remove files before you can create
new ones. Checked via
(2) Once logged into ARC, immediately obtain access to a compute node
(interactively) or schedule batch jobs as shown below. Do not
execute any other commands on the login node!
- interactively ("srun" has been depricated for interactive mode):
- salloc -n 16 # get 16 cores (1 node) in interactive mode
- mpicc -O3 /opt/ohpc/pub/examples/mpi/hello.c # compile MPI program
- prun ./a.out # execute an MPI program over all allocated nodes/cores
- in batch mode:
- compile programs interactively beforehand (see above)
- cp /opt/ohpc/pub/examples/slurm/job.mpi . # script for job
- cat /opt/ohpc/pub/examples/slurm/job.mpi # have a look at it, executes a.out
- sbatch job.mpi # submit the job, wait for it to get done:
creates job.%j.out file, where %j is the job number
- more slurm options:
- salloc -n 16 -N 1 # get 1 interactive node with 16 cores
- salloc -n 32 -N 2 -w c[90,91] #run on nodes 90+91
- salloc -n 64 -N 4 -w c[90-93] #run on nodes 90-93
- salloc -n 64 -N 4 -p broadwell #run on any 4 broadwell nodes
- salloc -n 64 -N 4 -p rtx2070 #run on any 4 nodes with RTX 2070 GPUs
- sinfo #available nodes in various queues, queues are listed in "Hardware" section
- squeue # queued jobs
- scontrol show job=16 # show details for job 16
- scancel 16 # cancel job 16
- Slurm documentation
- Slurm
command summary
- Editors are available once on a compute node:
- inside a terminal: vi, vim, emacs -nw
- using a separate window: evim, emacs

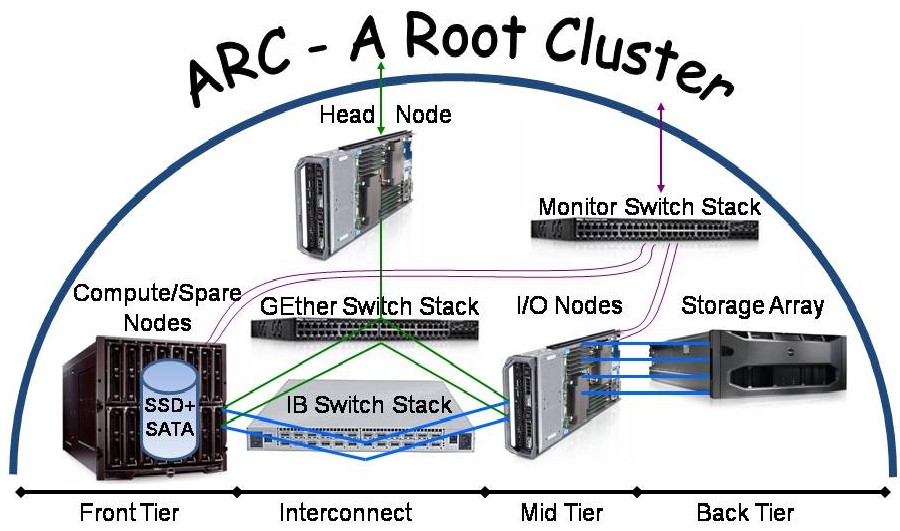
Hardware
1280 cores on 80 compute nodes integrated by
Advanced HPC. All machines are
2-way SMPs (except for single socket AMD Rome/Milan machines) with either
AMD or Intel processors (see below) and a total 16 physical cores per node (32 for c[30-31]).
Nodes:
- Intel Sandy Bridge: nodes c[67-70], queue: -p sandy
- Intel Ivy Bridge: nodes c[71-72], queue: -p ivy
- Intel Broadwell: nodes c[50-66], queue: -p broadwell
- Intel Skylake Silver: nodes c[0-19,26-29], queue: -p skylake
- AMD Epyc Rome: nodes c[20-25,33,37-49,73-79], queue: -p rome
- Intel Cascade Lake: nodes c[35-36], queue: -p cascade
- AMD Epyc Milan: nodes c[30-31,34], queue: -p milan
- AMD Epyc Genoa: nodes c[32], queue: -p genoa
- login node: arcl (1TB
HDD+Intel
X520-DA2 PCI Express 2.0 Network Adapter E10G42BTDABLK)
- nodes: cXXX, XXX=0..107 (1TB HDD)
- 16 nodes with NVIDIA Quadro P4000 (8 GB, sm 6.1): nodes c[0-3,8-19], queue: -p p4000
- 12 nodes with NVIDIA RTX 2060 (6 GB, sm 7.5): nodes c[26,29,51-57,60-62], queue: -p rtx2060
- 15 nodes with NVIDIA RTX 2070 (8 GB, sm 7.5): nodes c[50,63-67,69-76,79], queue: -p rtx2070
- 2 nodes with NVIDIA RTX 2080 (8 GB, sm 7.5): nodes c[24,28], queue: -p rtx2080
- 20 nodes with NVIDIA RTX 2060 Super (8 GB, sm 7.5): nodes c[21,25,34,37-49,58-59,68,78], queue: -p rtx2060super
- 2 nodes with NVIDIA RTX 2080 Super (8 GB, sm 7.5): nodes c[22-23], queue: -p rtx2080super
- 2 nodes with NVIDIA RTX 3060 Ti (8 GB, sm 8.6): node c[27,77], queue: -p rtx3060ti
- 6 nodes with NVIDIA RTX A4000 (16 GB, sm 8.6): node c[4-7,35-36], queue: -p a4000
- 2 nodes with 4 GPUs each NVIDIA RTX A6000 (48 GB, sm 8.6): node c[30-31], queue: -p a6000
- 1 node with NVIDIA A100 (80 GB, sm 8.6): node c[33], queue: -p a100
- 7 nodes with NVIDIA RTX 4060 Ti (8 GB, sm 8.7): node c[20-22,26-29], queue: -p rtx4060ti8g
- 1 node with NVIDIA RTX 4060 Ti (16 GB, sm 8.9): node c[25], queue: -p rtx4060ti16g
- 1 node with 3 GPUs each NVIDIA RTX A5000Ada (32 GB, sm 8.9): node c[30-31], queue: -p a5000ada
- head node: arcs (has 90TB RAID6 using 12xSAS3 10TB HDs (Seagate Exos X16 ST10000NM002G 10TB 7200 RPM) with
Supermicro
H12SSW-NTR Motherboard, Broadcom 3916 RAID controller AOC-S3916L-H16IR-32DD+ and
Transport
ASG-1014S-ACR12N4H plus a
10GEther
4xSPF+ Broadcom BCM57840S card 20Gbps bonded (dynamic link aggregation) to internal GEther switches
- backup node: arcm (same configuration as arch, except no 10GEther card)







|
Networking, Power and Cooling:
Pictures

System Status



Software
All software is 64 bit unless marked otherwise.

Obtaining an Account
- for NCSU students/faculty/staff in Computer Science:
- Send an email to your advisor asking for ARC access and indicate your unity ID.
- Have your advisor endorse and forward the email
to Subhendu Behera.
- If approved, you will be sent a secure link to upload your
public RSA key (with a 4096 key length) for SSH access.
- for NCSU students/faculty/staff outside of Computer Science:
- Send a 1-paragraph project description with estimated compute
requirements (number of processors and compute hours per job per
week) in an email to your advisor asking for ARC access and indicate your unity ID.
- Have your advisor endorse and forward the email
to Subhendu Behera.
- If approved, you will be sent a secure link to upload your
public RSA key (with a 4096 key length) for SSH access.
- for non-NCSU users:
- Send a 1-paragraph project description with estimated compute
requirements (number of processors and compute hours per job per
week) in an email to your advisor asking for ARC access. Indicate
the hostname and domain name that you will login from (e.g., sys99.csc.ncsu.edu).
- Have your advisor endorse and forward the email
to Subhendu Behera.
- If approved, you will be sent a secure link to upload your
public RSA key (with a 4096 key length) for SSH access.

Accessing the Cluster
- Login for NCSU users:
- Login to a machine in the .ncsu.edu domain (or use NCSU's VPN).
- Then issue (optional -X for X11 display):
- Or use your favorite ssh client under Windows from an .ncsu.edu
machine.
- Login for users outside of NCSU:
- Login to the machine that your public key was generated on.
Non-NCSU access will only work for IP numbers that have been
added as firewall exceptions, so please use only the computer
(IP) you indicated to us any other computer will not work.
- Then issue (optional -X for X11 display):
- Or use your favorite ssh client under Windows.

Using OpenMP (via gcc/g++/gfortran)
-
The "#pragma omp" directive in C/C++ programs works.
gcc -fopenmp -o fn fn.c
g++ -fopenmp -o fn fn.cpp
gfortran -fopenmp -o fn fn.f
-
To run under MVAPICH2 on Opteron nodes (4 NUMA domains over 16 cores),
it's best to use 4 MPI tasks per node, each with 4 OpenMP threads:
export OMP_PROC_BIND="true"
export OMP_NUM_THREADS=4
export MV2_ENABLE_AFFINITY=0
unset GOMP_CPU_AFFINITY
mpirun -bind-to numa ...
-
To run under MVAPICH2 on Sandy/Ivy/Broadwell nodes (2 NUMA domains over 16 cores),
it's best to use 2 MPI tasks per node, each with 8 OpenMP threads:
export OMP_PROC_BIND="true"
export OMP_NUM_THREADS=8
export MV2_ENABLE_AFFINITY=0
unset GOMP_CPU_AFFINITY
mpirun -bind-to numa ...

Running CUDA Programs (Version 12.3)

Running MPI Programs with MVAPICH2 and gcc/g++/gfortran (Default)
- Issue
module switch openmpi4 mvapich2
-
Compile MPI programs written in C/C++/Fortran:
mpicc -O3 -o pi pi.c
mpic++ -O3 -o pi pi.cpp
mpifort -O3 -o pi pi.f
-
Execute the program on, e.g., 2 processors (disabled on the login node, use
compute nodes via "salloc -n 2 ..." instead):
prun ./pi
-
Execute on a subset of the processors allocated by salloc (e.g., "salloc -n 32 ..."):
mpiexec.hydra -n 16 -bootstrap slurm ./pi
switch back to OPENMPI4:
module switch mvapich2 openmpi4

Running MPI Programs with Open MPI and gcc/g++/gfortran (Alternative)

Using the NVHPC/PGI compilers (V23.7 for CUDA 12.3)
(includes OpenMP and CUDA support via pragmas, even for Fortran)

Dynamic Voltage and Frequency Scaling (DVFS)
- Change the frequency/voltage of a core to save energy (without
any of with minor loss of performance, depending on how memory-bound
an application is)
- Use cpupower
and its
utilities
to change processor frequencies. Notice: When hyperthreading (ht) is
off, you can change one core at a time; but when ht if on, you
will need to change correspodning pairs of cores, e.g., (0,16) or
(1,17) etc. for 32 visible cores (adapt as needed).
- Example 1 for core 0 without hyperthreading (requires sudo rights):
- grep " ht " /proc/cpuinfo #should not produce any output; o/w see example 2
- cpupower frequency-info
- sudo cpupower -c 0 frequency-set -f 1500Mhz #set to userspace 1.5GHz
- watch cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq #should be nearly constant
- cpupower frequency-info
- sudo cpupower frequency-set -g ondemand #revert to original settings
- Example 2 for core (0,16) pair with hyperthreading (requires sudo rights):
- grep " ht " /proc/cpuinfo #should produce output
- cpupower frequency-info
- sudo cpupower -c 0 frequency-set -f 1500Mhz #set to userspace 1.5GHz
- sudo cpupower -c 16 frequency-set -f 1500Mhz #set to userspace 1.5GHz
- watch cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq #should be nearly constant
- cpupower frequency-info
- sudo cpupower frequency-set -g ondemand #revert to original settings

Power monitoring
Sets of three compute nodes share a power meter; in such a set,
the lowest numbered node has the meter attached (either on the serial
port or via USB). In addition, two individual compute nodes have power
meters (with different GPUs). See
this power wiring diagram to identify
which nodes belong to a set. The diagram also indicates if a meter
uses serial or USB for a given node. We recommend to explicitly
request a reservation for all nodes in a monitored set (see salloc
commands with host name option). Monitoring at 1Hz is accomplished
with the following software tools (on the respective nodes where
meters are attached):


Virtualization

BeeGFS
- cd /mnt/beegfs #to access it from compute nodes
- mkdir $USER #to create your subdirectory (only needs to be done once)
- chmod 700 $USER #to ensure others cannot access you data (only done once)
- cd $USER #go to directory where you should place your large files
- about 145TB of storage over 16 servers (9TB each)
- via 100Gpbs IB switch RDMA connection (ib0)
- Not protected by RAID, not backed up!

PAPI
- module load papi
- Reads hardware performance counters
- Check supported counters: papi_avail
- Edit your source file to define performance counter events,
read them and then print or process them, see
PAPI API
- Add to the Makefile compile options: -I${PAPI_INC}
- Add to the Makefile linker options: -L${PAPI_LIB} -lpapi

likwid
- module load likwid
- Pins threads to specific cores, avoids
Linux-based thread migration and may increase NUMA performance,
see likwid
project for a complete list of tools (power, pinning etc.)
- print NUMA core topology: likwid-topology -c -g
- Use likwid-pin
to pin threads to specific cores
- Example: likwid-pin myapp
- Example: mpirun -np 2 /usr/local/bin/likwid-pin ./myapp
- Use likwid-perfctr
or likwid-mpirun mearure performance counters, optionally with pinned threads
- Others: likwid-mpirun, likwid-powermeter, likwid-setfreq, ...


Big Data software: Hadoop, Spark, Hbase, Storm, Pig, Phoenix, Kafka, Zeppelin, Zookeeper, and Alluxio

Python

Tensorflow
- Tensorflow
- Option 1: install locally
- python3 -m pip install --upgrade --user pip #to upgrade pip
- pip3 install tensorflow
- Option 2: see
OpenHPC Exercise 4 -- Tensorflow under Horovod with Charliecloud
- for jupyter-notebook to work, issue
pip3 install jupyter seaborn pydot pydotplus graphviz -U --user
#set a password for your sessions (for security!!)
jupyter notebook password
#start the server
jupyter-notebook --NotebookApp.token='' --ip=cXX
#from your VPN/campus machine, assuming a port 8888 in the printed URL, issue:
ssh <your-unity-id>@arc.csc.ncsu.edu -L 8889:cXX:8888
#point your local browser at https://localhost:8889 and enter the password
- Notice: Anyone on ARC can now connect to cXX:8888, not just
you, and potentially write to your notebook, open other files in
this directory and subdirectories!
- Either use passwords (see above) or read about
secure
authentification for jupyter-nookbook for stronger protection.

PyTorch

Other Packges
A number of packages have been installed, please check out their
location (via: rpm -ql pkg-name) and documentation (see URLs) in this
PDF if you need them. (Notice, only the mvapich2/openmpi/gnu variants
are installed.) Typically, you can get access to them via:
module avail # show which modules are available
module load X
export |grep X #shows what has been defined
gcc/mpicc -I${X_INC} -L{X_LIB} -lx #for a library
./X #for a tool/program, may be some variant of 'X' depending on toolkit
module switch X Y #for mutually exclusive modules if X is already loaded
module unload X
module info #learn how to use modules
Current list of available modules (w/ openmpi4 active, similar lists
for other MPI variants):
------------------- /opt/ohpc/pub/moduledeps/gnu12-openmpi4 --------------------
adios/1.13.1 netcdf-fortran/4.6.0 scalapack/2.2.0
boost/1.80.0 netcdf/4.9.0 scalasca/2.5
dimemas/5.4.2 omb/6.1 scorep/7.1
extrae/3.8.3 opencoarrays/2.10.0 sionlib/1.7.7
fftw/3.3.10 petsc/3.18.1 slepc/3.18.0
hypre/2.18.1 phdf5/1.10.8 superlu_dist/6.4.0
imb/2021.3 pnetcdf/1.12.3 tau/2.31.1
mfem/4.4 ptscotch/7.0.1 trilinos/13.4.0
mumps/5.2.1 py3-mpi4py/3.1.3
netcdf-cxx/4.3.1 py3-scipy/1.5.4
------------------------ /opt/ohpc/pub/moduledeps/gnu12 ------------------------
R/4.2.1 mpich/3.4.3-ofi pdtoolkit/3.25.1
gsl/2.7.1 mpich/3.4.3-ucx (D) plasma/21.8.29
hdf5/1.10.8 mvapich2/2.3.7 py3-numpy/1.19.5
likwid/5.2.2 openblas/0.3.21 scotch/6.0.6
metis/5.1.0 openmpi4/4.1.4 (L) superlu/5.2.1
-------------------------- /opt/ohpc/pub/modulefiles ---------------------------
EasyBuild/4.6.2 nvhpc-hpcx-cuda12/23.7
autotools (L) nvhpc-hpcx/23.7
charliecloud/0.15 nvhpc-nompi/23.7
cmake/3.24.2 nvhpc/23.7
cuda (L) ohpc (L)
gnu12/12.2.0 (L) os
gnu9/9.4.0 papi/6.0.0
hwloc/2.7.0 (L) prun/2.2 (L)
libfabric/1.13.0 (L) singularity/3.7.1
magpie/2.5 ucx/1.11.2 (L)
nvhpc-byo-compiler/23.7 valgrind/3.19.0
nvhpc-hpcx-cuda11/23.7

Advanced topics (pending)
For all other topics, access is restricted. Request a root password.
Also, read this documentation, which is only
accessible from selected NCSU labs.
This applies to:
- booting your own kernel
- installing your own OS

Known Problems
Consult the FAQ. If this does not help, then
please report your problem.
References:
- A User's
Guide to MPI by Peter Pacheco
- Debugging: Gdb only works on one task with MPI, you need to
"attach" to other tasks on the respective nodes. Another trick is to
spawn terminals for each MPI rank: mpirun -np 2 /usr/bin/xterm -e
gdb ./[my-a.out] or even start running with mpirun -np 2
/usr/bin/xterm -e gdb -ex run --args ./[my-a.out] [pgm-args]. We
don't have totalview (an MPI-aware debugger), but it's available for
free for students, though you would have to install it yourself. You
can also use printf debugging, of course. If your program SEGVs, you
can set ulimit -c unlimited and run the mpi program again,
which will create one or more core dump files (per rank) named
"core.PID", which you can then debug: gdb binary and
then core core.PID.

Additional references:



{kind=link}
{kind=link}